
How we leveraged our experience in image processing and compression to build a better AI accelerator (and made it easy-to-use in the process).
Our path to developing an AI vision architecture started with a question: Is it possible to build a fast, intelligent, and powerful system capable of running the latest neural networks with minimum effort, high precision, and low power consumption?
Said differently: What would it take to create a dedicated AI accelerator designed specifically for low-power embedded systems at the edge, with performance that rivals—or even exceeds—the performance of systems that rely on the cloud?
We began our investigations in 2015. At the time, emerging research had demonstrated that face recognition and object detection could be implemented successfully in an embedded platform, and our customers were increasingly interested in intelligent vision systems, as opposed to traditional cameras.
Prior to that, Ambarella’s core strength had been our dedicated hardware accelerators for video compression, (notably H.264 and H.265) as well as image processing that delivers exceptional image quality in a variety of challenging lighting conditions, all while consuming minimal power. To build these accelerators, we carefully studied the problem and designed custom hardware that executes the critical tasks well, while discarding concepts or options that provide little benefit or are too complex to implement effectively. For over a decade, we used these accelerators to help launch dozens of industry-defining video products in both consumer and professional markets: the original line of GoPro Hero sports cameras, the Dropcam home security device, and the DJI Phantom drone series, to name just a few.



Therefore, when it came time to build an embedded architecture for computer vision processing, we followed a similar path, using the same methodology that succeeded before, combining existing design elements with new concepts to address the unique challenges of AI. After studying common algorithms in traditional computer vision, emerging techniques in convolutional neural networks, and the autonomous driving algorithm stack developed by VisLab (acquired by Ambarella in 2015), we developed an elegant piece of hardware that is lean, mean, and highly practical—known as CVflow®.
The roots of a new architecture.
Like everyone, we started with neural networks. Their advantages are well-documented, including: (a.) only a few critical operations dominate performance, notably convolutions and matrix operations; and (b.) the math involved is straightforward with ample parallelism. The most obvious architectural approach would have been to deploy an army of processors (e.g., GPUs) or large multiplier array (e.g., TPU), which delivers an immediate gain in neural network performance. However, this approach wasn’t suitable for the low-power embedded devices our customers were envisioning.
“From the outset, our objective was to create a streamlined architecture from the ground up with neural network processing as the sole priority.”
Rather than relying on existing general-purpose solutions, we spent years studying all aspects of neural network-based processing to design an engine optimized specifically for the embedded market, with the express goal of eliminating bottlenecks and inefficiencies present in GPUs or TPUs. From the outset, our objective was to create a streamlined architecture from the ground up with neural network processing as the sole priority. Our success required creativity, critical analysis of ideas, a discussion of design tradeoffs among our VLSI, architecture, and software teams, and ultimately solving complex problems with consensus. After three years of research, experimentation, and highly focused collaboration, CVflow was born.
In my academic career, I studied the history of processor design—from small processors to large cache-coherent multiprocessors used for scientific research, VLIW-based machines, IA-64, GPUs, SIMD machines, and more. What I learned during that time was that the most notable architectures tended to solve a specific problem in an innovative way that stood out relative to competing ideas of the day. For example, RISC machines were considered important because they were much easier to pipeline effectively and more straightforward to program than their plodding CISC-based counterparts. Our CVflow architecture similarly stands out as a highly optimized and innovative solution to computer vision and inference acceleration.
But is it user-friendly?
Any accelerator, regardless of its purpose, can be challenging to work with. Knowing this, we’ve cultivated an intuitive and painless programming model for CVflow since its inception. Our previous approach—wrapping a clean API around a complex piece of powerful hardware to provide a simple user interface—wasn’t an option in an environment where customers have their own networks, and where networks change rapidly. Moreover, managing computation precision was a critical concern for our customers in order to ensure that their networks would continue to perform well on our SoCs. These and other considerations were at the forefront of our minds as we developed the CVflow architecture.
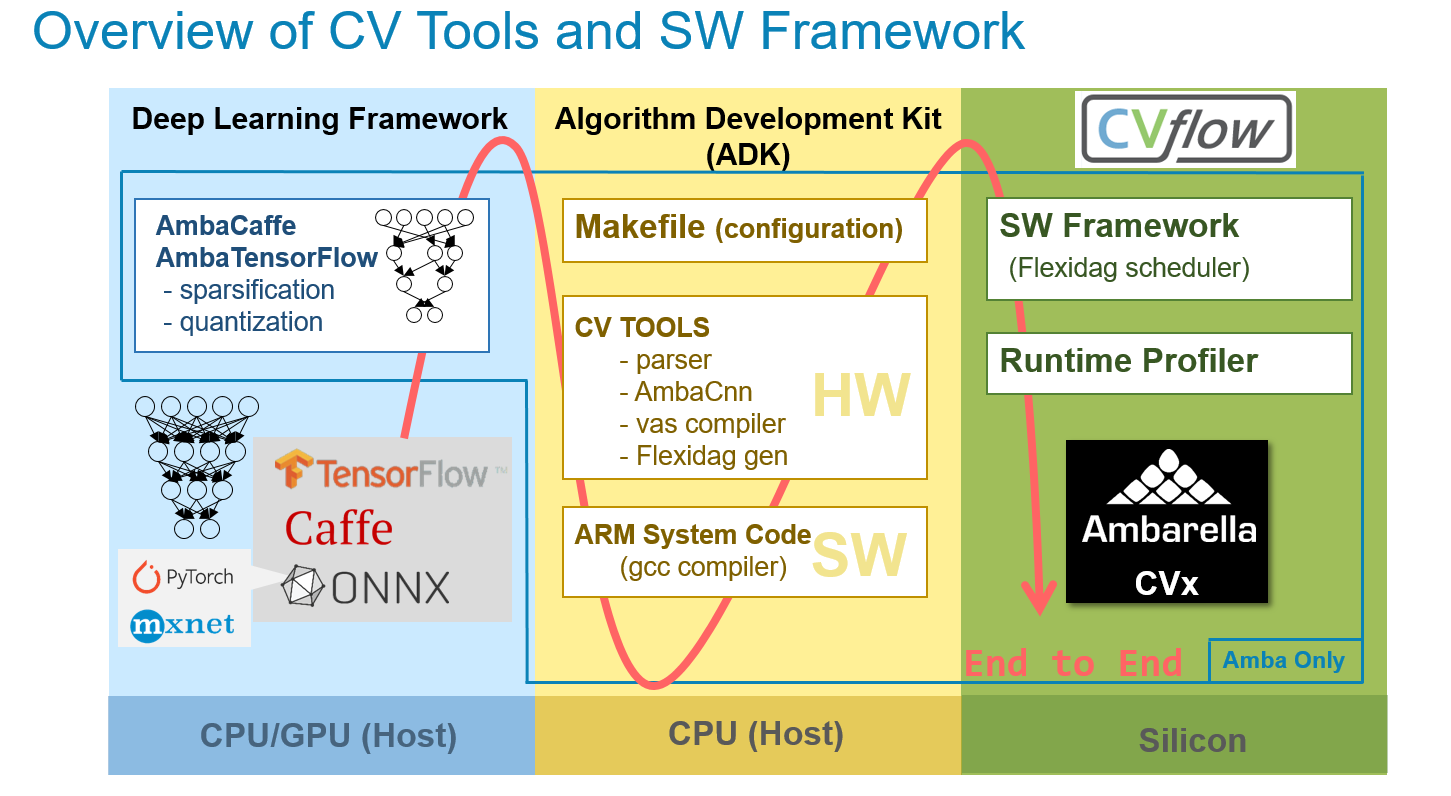
To make programming as easy as possible for our customers, we dedicated significant time and resources to the development of our CVflow compiler and network mapping tool (CNNGen), constructing a tool stack that reads a high-level specification of a network in TensorFlow or PyTorch and optimizes the network to run on our hardware, while simultaneously providing enough control so that the user achieves nearly the same level of accuracy as their original high-precision networks. This tool stack, built on top of our CVFlow architecture, is powerful enough to extract the best performance from the device, yet also flexible enough to be integrated into external services such as Sagemaker NEO from Amazon Web Services, which allows customers to adapt their architectures and networks to our hardware on the cloud.
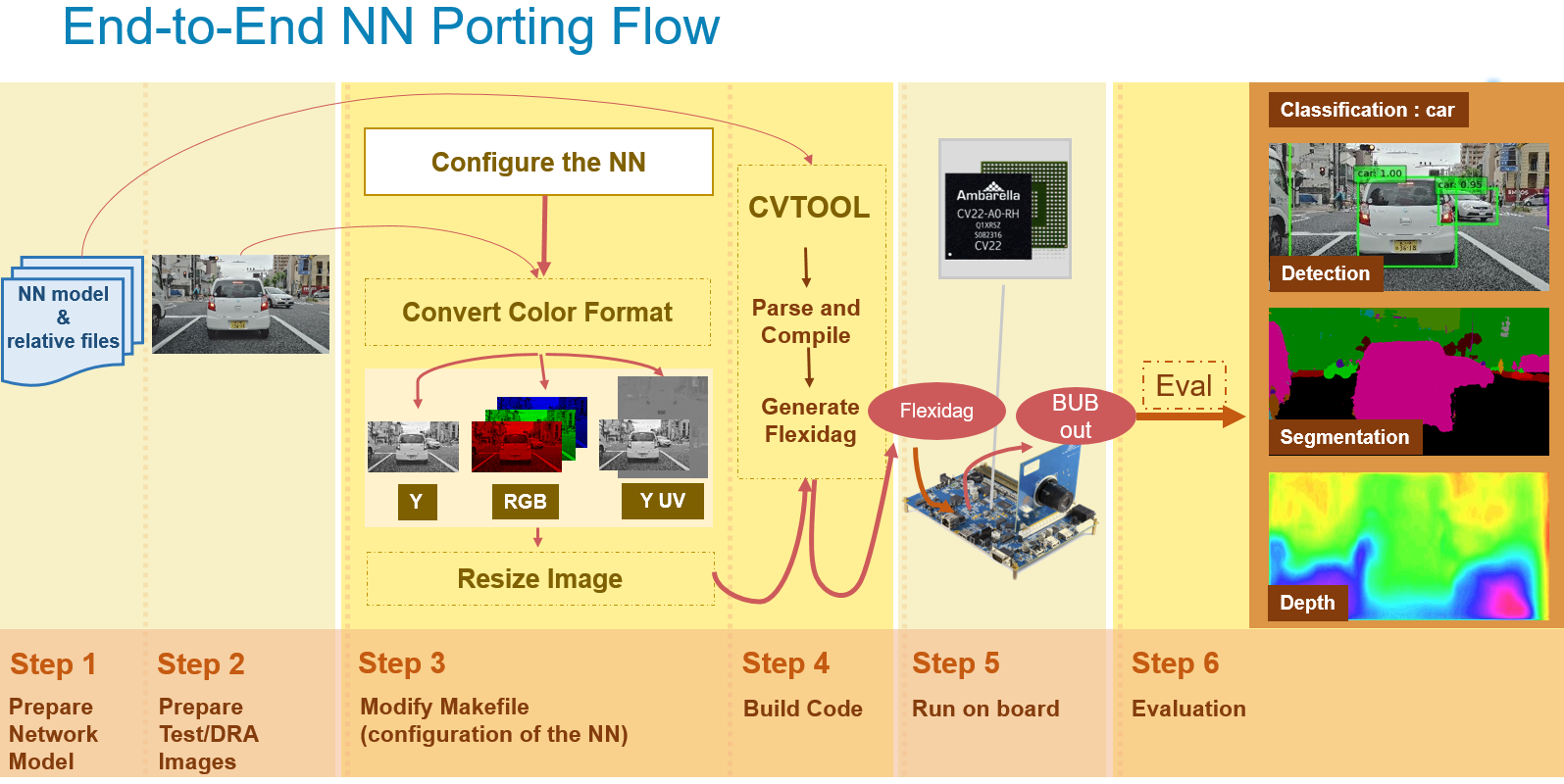
Using this robust set of tools, our internal teams, partners, and customers have adapted over 200 neural networks to our architecture so far. Ported networks address a wide range of use cases including 2D/3D objection detection, segmentation, and optical flow, and have achieved reasonable accuracy in very little time—generally within hours. And, importantly, we open our tools to all network topologies, rather than limiting users to a restricted set of topologies designed only to make us look good.
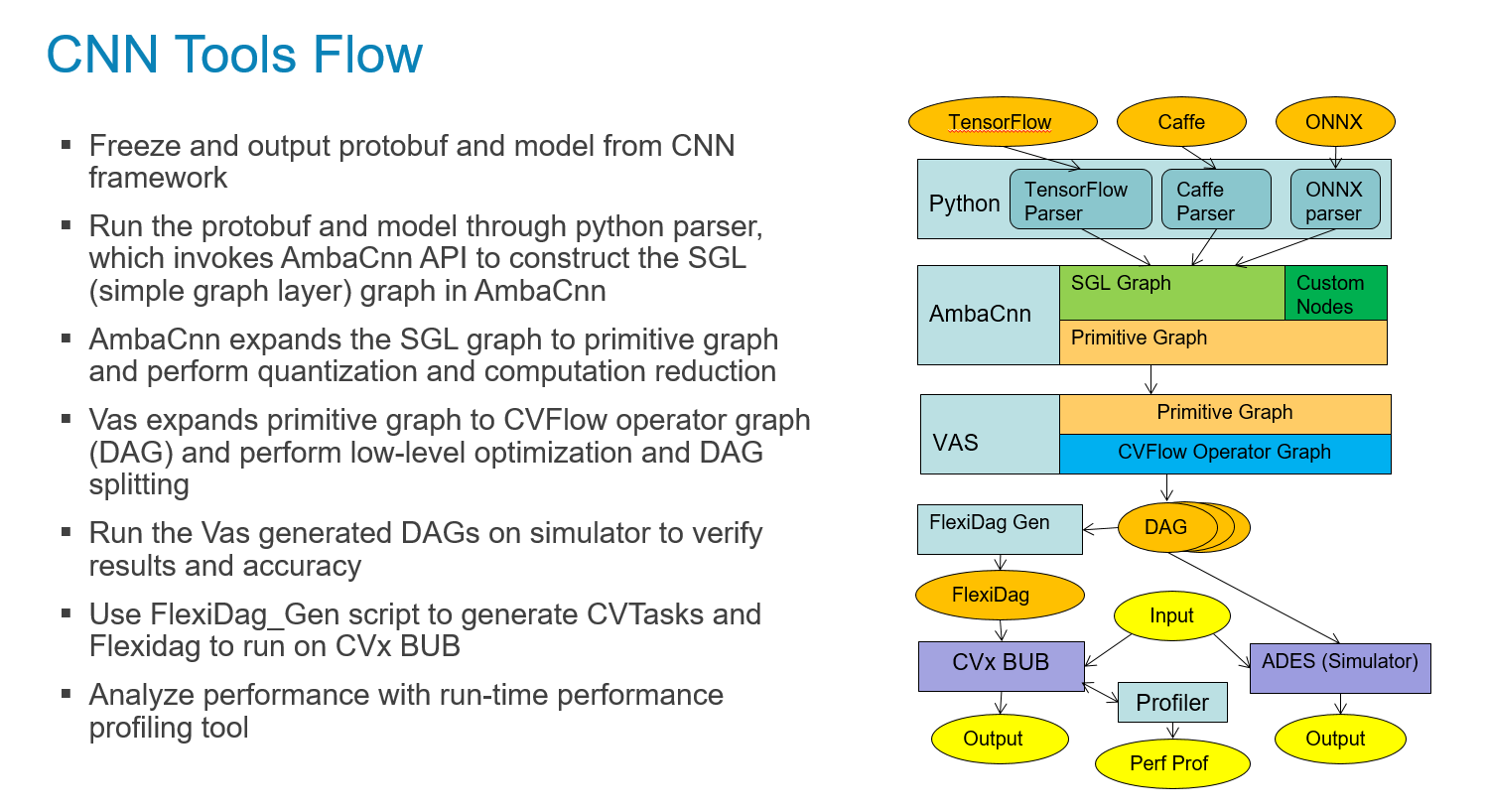
We are adding new networks daily as more customers use our toolchain. In turn, each new network improves our overall quality as they add new complexity and layers to the tool stack, built on top of the same architecture. The longer I work on this design, the more I appreciate CVflow’s flexibility to adapt to changing trends in computer vision, which are only accelerating over time. Neural networks look much different now than when we started, but our architecture continually adapts by incorporating new layers and requirements to keep pace, all customized and optimized for high-performance and low-power operations.
To learn more about our embedded low-power CVflow architecture, or if you’re interested in using our toolchain to rapidly adapt your own state-of-the-art networks to run on our hardware, please contact us.